
Pour donner suite à mon premier article sur le machine learning, son fonctionnement et son utilité, je vous propose de continuer cette série en s'intéressant aux différents types de machine learning.
Le machine learning ou apprentissage automatique est un ensemble de méthodes qui offre aux systèmes la possibilité de faire et d’améliorer des prédictions ou des comportements basés sur des données sans être explicitement programmés.
Dans le domaine du machine learning, il n’existe pas un algorithme unique qui permet de s’attaquer à n'importe quel problème. Au contraire, les avancées mathématiques et technologiques nous offrent un ensemble très varié de techniques d’apprentissage qui s’adaptent plus ou moins bien à certains types de problèmes. En fonction du problème à résoudre et des données à disposition, certaines méthodes fournissent d’excellent résultats là où d’autres sont inadaptées.
Pour sélectionner la méthode de machine learning la plus efficace pour résoudre un problème, il est donc nécessaire d’apprendre à connaître les types d'algorithmes d'apprentissage automatique.
Il existe plusieurs approches pour classifier ces algorithmes de machine learning. Dans cet article nous nous intéressons aux grands types d’apprentissage.
Apprentissage supervisé
L'apprentissage supervisé est défini par l’utilisation d'ensembles de données étiquetés pour entrainer des algorithmes qui classent les données ou prédisent les résultats avec précision.
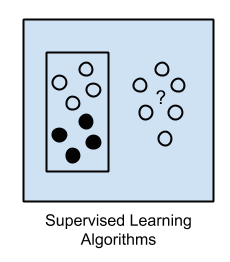
Au fur et à mesure que les données d'entrée sont introduites dans le modèle, il ajuste ses pondérations grâce à un processus d'apprentissage par renforcement, qui garantit que le modèle a été ajusté de manière appropriée.
💡 L'apprentissage supervisé aide les organisations à résoudre divers problèmes du monde réel à grande échelle, tels que la classification des courriels indésirables ou la détection de cellule cancéreuse.
Apprentissage non-supervisé
L'apprentissage non supervisé utilise des algorithmes d'apprentissage automatique pour analyser et regrouper des ensembles de données non étiquetés. Ces algorithmes découvrent des modèles cachés ou des regroupements de données sans intervention humaine.
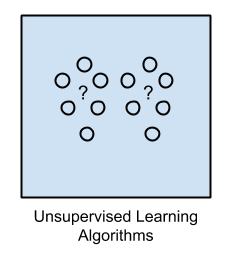 Leurs capacités à découvrir les similitudes et les différences d'informations en font des solutions idéales pour l'analyse exploratoire des données, les stratégies de vente croisée, la segmentation de la clientèle et la reconnaissance d'image.
Leurs capacités à découvrir les similitudes et les différences d'informations en font des solutions idéales pour l'analyse exploratoire des données, les stratégies de vente croisée, la segmentation de la clientèle et la reconnaissance d'image.
Apprentissage semi-supervisé
L'apprentissage semi-supervisé est une autre classe de processus et de technique d'apprentissage automatique qui utilise un mélange de données étiquetées et non étiquetées.
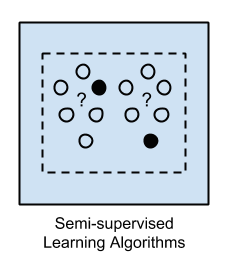 Les données non étiquetées sont utilisées pour l'entraînement du modèle (tout comme l'apprentissage non supervisé) et généralement, une petite proportion de données étiquetées est introduite et utilisée dans cette phase d’apprentissage. L’apprentissage semi-supervisé utilise donc des données partiellement étiquetées.
Les données non étiquetées sont utilisées pour l'entraînement du modèle (tout comme l'apprentissage non supervisé) et généralement, une petite proportion de données étiquetées est introduite et utilisée dans cette phase d’apprentissage. L’apprentissage semi-supervisé utilise donc des données partiellement étiquetées.
L'apprentissage semi-supervisé se place entre l'apprentissage non supervisé (sans données d'entraînement étiquetées) et l'apprentissage supervisé (avec des données d'entraînement entièrement étiquetées).
Les programmes d'apprentissage semi-supervisé utilisent des hypothèses standard comme la continuité, le clustering et la variété sur le jeu de données pour les aider à utiliser les données non étiquetées dans l’entrainement du modèle.
Apprentissage par renforcement
L'apprentissage par renforcement (RL) est un type de technique d'apprentissage automatique qui permet à un agent d'apprendre dans un environnement interactif par essais et erreurs en utilisant les retours sur ses propres actions et expériences.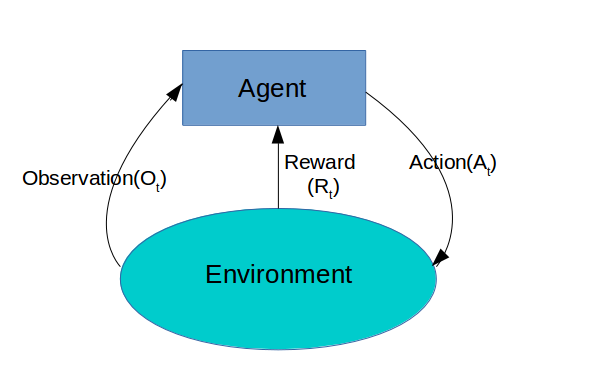 Contrairement à l'apprentissage supervisé où le retour d'information fourni à l'agent est un ensemble correct d'actions pour exécuter une tâche, l'apprentissage par renforcement utilise les récompenses positives ou négatives comme signaux de comportements adéquats ou inadaptés.
Contrairement à l'apprentissage supervisé où le retour d'information fourni à l'agent est un ensemble correct d'actions pour exécuter une tâche, l'apprentissage par renforcement utilise les récompenses positives ou négatives comme signaux de comportements adéquats ou inadaptés.
💡 Par rapport à l'apprentissage non supervisé, l'apprentissage par renforcement est différent en termes d'objectifs. Alors que le but de l'apprentissage non supervisé est de trouver des similitudes et des différences entre les points de données, dans l'apprentissage par renforcement, l'objectif est de trouver un modèle d'action approprié qui maximise la récompense cumulative totale de l'agent.
Pour conclure, la sélection d’un type d’apprentissage va généralement se décider en fonction des données à disposition (étiquetés ou non) et du problème à résoudre. Ensuite il s’agit de savoir quel type de résultat est attendu de l’algorithme pour affiner le choix de modèles à entrainer.
Dans un prochain article, je vous propose d'autre sujets de data intelligence en continuant à explorer les techniques de machine learning en s’intéressant au fonctionnement des grands groupes d’algorithmes d’apprentissage automatique.

