
What is behind the concept of tidy data ?
Tidy dataset are all alike; every messy dataset ismessy in
its own way
In the world of data science, you will often hear about cleaning and preparing data. In my previous articles on data management and data literacy, I describe the different steps which are the foundations for extracting value out of data. This is because a large part of the data science activities consists of cleaning, manipulating, improving, enriching and preparing datasets so that they can then be used optimally and comprehensively.
To give you an idea, about 80% of data analysis is spent on cleaning and preparing data. And this is not a one time thing! It is usually repeated several times during the analysis as new problems arise or new data is collected.
The goal is to obtain clean datasets which can then be used for analysis and then modeling. The cleaning steps make it possible to structure the datasets and to facilitate their use in a rigorous and reproducible manner.
This is why the principles of tidy data provide a standard way to organize data in a dataset.
Vocabulary
Let's start with a few words of vocabulary:
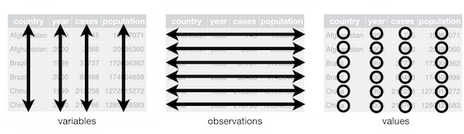
- A variable: a quantity, quality or property that can be measured
- An observation: a set of values that demonstrates the relationship between variables. To create an observation, the values must be measured under similar conditions and generally on the same observation unit and at the same time.
- A value: the observed state of a variable at the time of measurement
Definition
The principle of tidy data is based on the following three conditions:
- Each variable in its own column
- Each observation on its own line
- Each value in its own cell
With this standard in mind, data cleaning is made easier because the goal is clear. In addition, the analysis work is also made easier because there is no longer any need to go back several times to the processing and manipulation of the data to ensure its consistency.
Common breaches of tidy data principles
Here is a non-exhaustive list of breaches of the principles of tidy data from random data:
❌Column headers are values
A common type of messy data is tabular data designed for presentation, where variables are in both rows and columns, and column headers are values, not variable names.
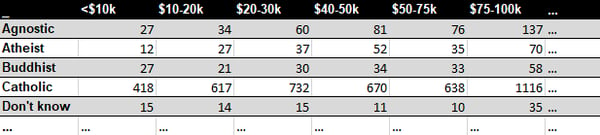
This dataset contains three variables: religion, income and frequency. By applying the principles of tidy data, we obtain the following result:
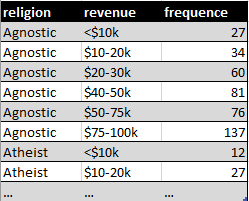
This dataset is now tidy. Each column represents a variable and each row an observation which in this case is a demographic unit corresponding to a combination of religion and income.
❌The variables are contained in both rows and columns
The most complicated form of messy data occurs when variables are stored in both rows and columns:
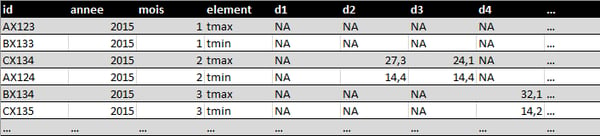
This dataset contains variables in individual columns (id, year, month), distributed over columns (day, d1-d31) and over rows (tmin, tmax for minimum and maximum temperature). Months with less than 31 days have missing structural values for the last day(s) of the month.
After processing, here is the tidy dataset that meets the principles of tidy data:
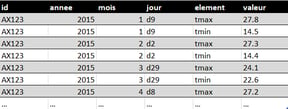
❌Several types of observation units are stored in the same table
Datasets often involve values collected at multiple levels and on different types of observation units. When storing, each type of observation unit should be stored in its own table. This is closely related to the idea of database standardization, where every observation is expressed in one place. This is important because otherwise inconsistencies can arise and spread throughout the analysis.
Most messy datasets, including the types of problems not explicitly described above, can be fixed. This requires the use of data manipulation tools such as for example the pandas and dplyr libraries of the Python and R languages respectively
To conclude, the principles of tidy data are essential in the manipulation of data for uses in data analysis and more broadly in the field of data science. I hope this article has given you a better understanding of this concept and helped you grow your knowledge of data!
Note: to go further, Hadley Wickham's 2014 super paper, Tidy Data, describes the entire process of cleaning and organizing a dataset in the R language.
