
Peut-être avez-vous déjà entendu parler du data management, mais saviez-vous que ces processus permettaient d'apporter davantage de valeur à la donnée ?
Suite aux retours qui ont suivis mon dernier article "Data manager, c'est quoi mon métier ?" où je décris le métier de Data Manager chez Avanci, agence conseil data et CRM, voici un rapide aperçu du data management qui, je l’espère, répondra aux questions qui m'ont été posées !
Chez Avanci, les data managers sont principalement investis dans la construction de Customer Data Plateform (CDP).
Pour en savoir plus sur le sujet : DMP, DWH, TMS : Les technologies souvent confondues avec les CDP
La mise en place d’une CDP passe par plusieurs étapes importantes qui font le cœur du métier du data manager.
Qualifier et paramétrer
Pour commencer, les sources de données sont généralement multiples, et le format de stockage de ces données l'est également.
La première étape consiste à paramétrer les accès à ces données, déterminer les formats de données et s’assurer que les différents flux sont stables.
Par exemple, les données peuvent être transférées via fichier plat (CSV) depuis le logiciel de gestion du client (ERP). Il faut alors faire en sorte que la structure des données exportées corresponde au modèle de donnée attendu. Dans d’autres cas, il est nécessaire d'interroger une API (Application Programming Interface, ou interface de programmation) pour récupérer les données. Il est aussi possible de s’interfacer directement avec les bases de données du client.
Chaque source a ses spécificités qu’il faut prendre en compte pour assurer le bon fonctionnement du data pipeline. D’autres questions se posent également, comme la fréquence de collecte des données, la taille et la planification des flux.
En fonction de la taille du client, des types de données qu’il possède et des besoins qu’il a, il est possible de se retrouver avec des quantités de données très variables. Entre une base de données client d’une dizaine de milliers de lignes et une de plusieurs millions, les technologies et techniques pour gérer ces volumes peuvent varier. Le data manager doit donc faire les bons choix de paramétrage et anticiper afin d’optimiser par exemple le temps d’intégration et de traitement, l’accès aux données ou les fréquences de traitement.
Ensuite, une fois les systèmes en production, des routines sont mises en place pour fournir régulièrement des mesures de cohérence. Ces informations sont alors mises à disposition dans des dashboards pour suivre l’évolution d’indicateurs, être alerté en cas d’anomalies et ainsi pouvoir intervenir rapidement si nécessaire.
Pour aider à visualiser à quoi la donnée brute ressemble, voici deux exemples de données fictives sous différents formats :
- Format CSV (Comma Separated Value)

- Format JSON (JavaScript Object Notation)
Intégrer et organiser
Une fois que l'on a la donnée brute, il s'agit ensuite de l'intégrer et de l'organiser.
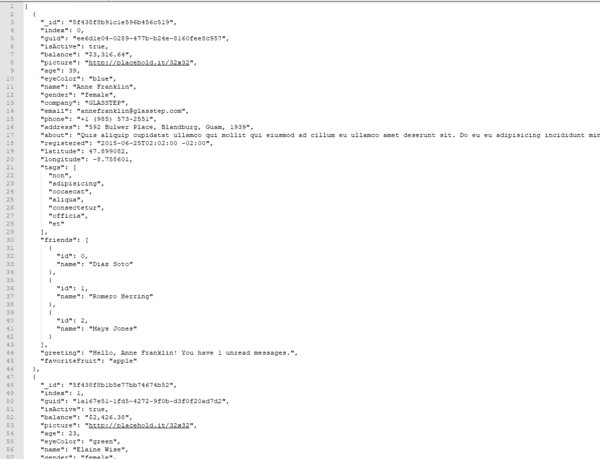
A partir des fichiers CSV ou JSON ci-dessus, voici un exemple de résultat attendu. Il s’agit d’une table dans une base de données SQL (Structured Query Language).
Une base de données sert essentiellement à stocker des informations (comme des noms, prénoms, adresses, numéros de téléphone, données d’achat, et autres) pour ensuite être capable de les traiter, les filtrer et les trier afin d'en extraire des statistiques ou de récupérer les données d'un individu à partir de son nom par exemple.
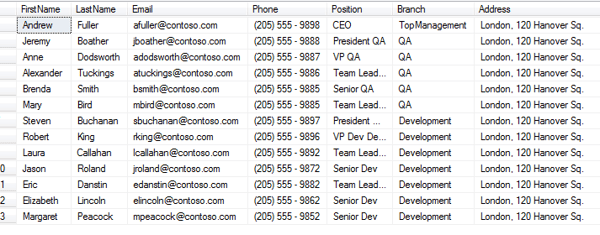
La base de données peut contenir plusieurs tables comme celles-ci qui sont reliées à l’aide de clés :
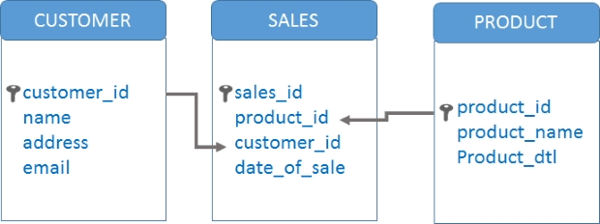
Pour faciliter les accès aux données pour des applications futures d’analyse ou autre, le data manager possède différentes techniques pour organiser la donnée. Par exemple, l’éclatement d’une table pour séparer les données primaires des données secondaires. Cela permet d’alléger la structure de la base de données sans compromettre sa cohérence.
Un autre exemple, la mise en place de table virtuelle dans la base de données permet de présenter certaines informations sans avoir à créer de nouvelles tables ce qui procure de la flexibilité.
Traiter et enrichir
Une fois l’intégration et l’organisation des données effectués, la troisième étape du data management commence. Il s’agit de nettoyer, redresser, enrichir et préparer la donnée.
En fonction des besoins du client et des futures utilisations des données, les traitements peuvent varier et être plus ou moins complexes.
Voici quelques exemples de nettoyage de données :
- Redressement ou exclusion des adresses emails invalides

- Mise en forme des nom et prénom d’un contact suivant un standard

- Nettoyage et normalisation des numéros de téléphone

Le data manager possède aussi plusieurs techniques pour augmenter la valeur de la donnée. Cela se traduit par l’ajout de champ de valeur calculés tels que :
- Le genre : par la réconciliation du prénom sur une base de l’INSEE pour trouver le genre correspondant
- La civilité : par l’attribution d’une civilité à partir du genre
- L'identification des contacts client et des contacts prospect : par la recherche de commandes passées par le contact
- Le redressement de l’adresse postale pour assurer qu’un envoi de courrier arrive bien à l’adresse renseignée ou pour faire de l’analyse géographique
- La vérification de la validité de l’adresse email pour s'assurer qu’il ne s’agisse pas d’adresses pièges ou exclues par les fournisseurs d’accès
- La déduplication des contacts dans la base de données qui permet d’assainir la base de contacts en créant une fiche principale regroupant l’ensemble des informations des fiches secondaires rattachées.
Enfin, la dernière étape d’enrichissement passe par le calcul d’agrégats et d’indicateurs spécifiques aux besoins d’exploitation de la donnée.
Parmi ces indicateurs, il y a par exemple :
- Le nombre total de commandes pour un contact
- Le nombre de jours depuis la dernière commande
- Le montant du panier moyen
- Le magasin préféré basé sur des schémas comportementaux
- La mesure d'un taux de réponse à un événement marketing
- La segmentation des clients pour identifier les VIP ou les clients abandonnistes.
Cette liste n’est qu’un aperçu et il est possible d’imaginer une multitude d’informations qui peuvent être calculées, agrégées ou attribuées dans le modèle de données.
Pour finir, le travail de data management n’est pas complet sans une planification de toutes ces tâches et l’assurance que tous les pipelines et processus fonctionnent de manière autonome. Il s’agira donc d’optimiser les flux et traitements avant la mise en production pour minimiser le besoin d’intervention humaine par la suite

