
Qu'est-ce qui se cache derrière le concept de données propres ou ordonnées ?
"Les ensembles de données ordonnés sont tous semblables ; chaque ensemble de données désordonné l’est à sa manière", Hadley Wickham, Chief Scientist at RStudio, membre de la R Foundation, Adjunct Professor at Stanford University and the University of Auckland
Dans le monde de la data, vous entendrez souvent les termes de nettoyage de données, préparation de la donnée et stockage de la donnée. Dans mes articles précédents, notamment celui du data management et sur la culture de la donnée, je passe beaucoup de temps à décrire les étapes qui constituent les fondations de l’exploitation de la big data et de son potentiel. Cela s’explique par le fait qu’une grande partie des activités dans le domaine de la data science consiste à nettoyer, manipuler, améliorer, enrichir et préparer des ensembles de données pour qu’ils puissent ensuite être exploités de manière optimale et complète. C'est le cœur de la data intelligence !
Pour vous donner un ordre d'idée, en entreprise, environ 80% de l'analyse des données est consacrée au nettoyage et à la préparation des données. Et ce n’est pas seulement une première étape ! Elle doit être répétée plusieurs fois au cours de l’analyse à mesure que de nouveaux problèmes apparaissent ou que de nouvelles données sont collectées.
L’objectif est d’obtenir des ensembles de données ordonnées, ou “propres”, qui pourront servir à l’analyse, puis à la modélisation. Les étapes de nettoyage permettent ainsi de structurer les ensembles de données pour faciliter leur exploitation de manière rigoureuse et reproductible.
C’est pourquoi les principes de tidy data fournissent une manière standard d'organiser les valeurs de données dans un système de données.
Sémantique de la donnée propre
Commençons par quelques mots de vocabulaire :
- Une variable : une quantité, qualité ou propriété que l’on peut mesurer.
- Une observation : un ensemble de valeurs qui démontre la relation entre les variables. Pour constituer une observation, les valeurs doivent être mesurées dans des conditions similaires et généralement sur la même unité d'observation et au même moment.
- Une valeur : l’état observé d’une variable au moment de la mesure.
La tidy data, qu'est-ce que c'est ?
Le principe de tidy data repose sur les trois conditions suivantes :
- Chaque variable dans sa propre colonne
- Chaque observation sur sa propre ligne
- Chaque valeur dans sa propre cellule
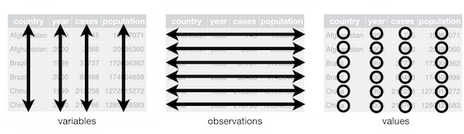
Avec cette norme, les systèmes de nettoyage des données est facilité car l’objectif à atteindre est clair. De plus, le travail d’analyse s’en trouve facilité car il n’y a plus besoin de revenir plusieurs fois sur le traitement et la manipulation de la donnée pour s’assurer de sa cohérence.
Business intelligence et data visualisation : quels enjeux ?
Infractions courantes aux principes du tidy data
Voici une liste non exhaustive d’infractions aux principes de tidy data à partir de données aléatoires.
❌ Les en-têtes de colonnes ne doivent pas être des valeurs
Un type courant d'ensemble de données désordonnées sont les données tabulaires conçues pour la présentation, où les variables forment à la fois les lignes et les colonnes, et les en-têtes de colonne sont des valeurs, pas des noms de variables.
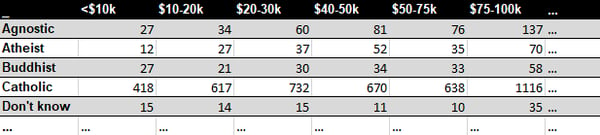
Cet ensemble de donnée contient trois variables : religion, revenue et fréquence, mais vous voyez que la lecture du tableau ci-dessus est rendue difficile. En appliquant les principes de tidy data, nous obtenons le résultat d'informations suivant :
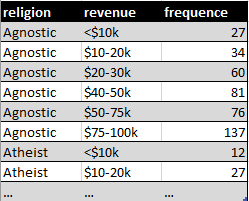
Cette forme est ordonnée car chaque colonne représente maintenant une variable et chaque ligne une observation. Ici, l'observation est une unité démographique correspondant à une combinaison de l'information religion et du revenu.
❌Les variables ne doivent pas être contenues à la fois dans les lignes et les colonnes
La forme la plus compliquée de données désordonnées se produit lorsque les variables sont stockées à la fois dans des lignes et des colonnes :
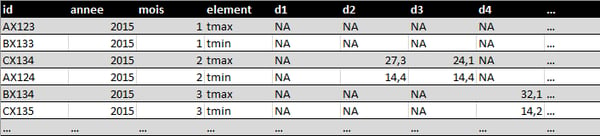
L'ensemble de données ci-dessus comporte des variables dans des colonnes individuelles (ID, année, mois), réparties sur les colonnes (jour, d1-d31) et sur les lignes (température minimale et maximale). Les mois avec moins de 31 jours ont des valeurs structurelles manquantes pour le ou les derniers jours du mois.
Après recherche et manipulation, voilà l’ensemble de données ordonné qui répond aux principes de tidy data :
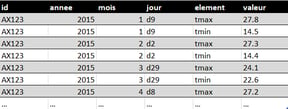
❌Plusieurs types d'unités d'observation ne doivent pas être stockés dans la même table
Les ensembles de données impliquent souvent des valeurs collectées à plusieurs niveaux, sur différents types d'unités d'observation. Lors du rangement, chaque type d'unité d'observation doit être stocké dans sa propre table.
Ceci est étroitement lié à l'idée de normalisation de la base de données, où chaque fait est exprimé en un seul endroit. C’est important car sinon des incohérences peuvent survenir et se propager dans l’analyse.
La plupart des ensembles de données désordonnés, y compris les types de désordre non décrits explicitement ci-dessus, peuvent être rangés. Cela nécessite l’utilisation d’outils de manipulation de la donnée, comme par exemple les librairies Pandas et dplyr des langages Python et R respectivement.
Pour conclure, les principes de tidy data sont essentiels dans la manipulation des données pour des utilisations en data analyse et de manière plus large dans le domaine de la science des données. J’espère que cet article vous aura permis de mieux appréhender ce concept et d'alimenter votre culture data ! À noter pour les anglophiles et les passionnés, le super papier d’Hadley Wickham publié en 2014, Tidy Data, qui décrit l’ensemble du process de nettoyage et de l'organisation d’un ensemble de donnée dans le langage R.
Cela risque de vous intéresser :

